The following packages are required for the random forest
if(!require(tidyverse)){install.packages("tidyverse");library(tidyverse)}
if(!require(janitor)){install.packages("janitor");library(janitor)} # for rename
if(!require(randomForest)){install.packages("randomForest");library(randomForest)}
if(!require(caret)){install.packages("caret");library(caret)} # for `confustionMatrix`A Random forest is made of Random Trees
Data <- read_csv(file = here::here("content/post/2022-06-26-random-forest", "german_credit.csv"))Exploring the dataset
Data <- clean_names(Data)
Data$creditability <- as.factor(Data$creditability)
glimpse(Data)
## Rows: 1,000
## Columns: 21
## $ creditability <fct> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
## $ account_balance <dbl> 1, 1, 2, 1, 1, 1, 1, 1, 4, 2, 1, 1, …
## $ duration_of_credit_month <dbl> 18, 9, 12, 12, 12, 10, 8, 6, 18, 24,…
## $ payment_status_of_previous_credit <dbl> 4, 4, 2, 4, 4, 4, 4, 4, 4, 2, 4, 4, …
## $ purpose <dbl> 2, 0, 9, 0, 0, 0, 0, 0, 3, 3, 0, 1, …
## $ credit_amount <dbl> 1049, 2799, 841, 2122, 2171, 2241, 3…
## $ value_savings_stocks <dbl> 1, 1, 2, 1, 1, 1, 1, 1, 1, 3, 1, 2, …
## $ length_of_current_employment <dbl> 2, 3, 4, 3, 3, 2, 4, 2, 1, 1, 3, 4, …
## $ instalment_per_cent <dbl> 4, 2, 2, 3, 4, 1, 1, 2, 4, 1, 2, 1, …
## $ sex_marital_status <dbl> 2, 3, 2, 3, 3, 3, 3, 3, 2, 2, 3, 4, …
## $ guarantors <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
## $ duration_in_current_address <dbl> 4, 2, 4, 2, 4, 3, 4, 4, 4, 4, 2, 4, …
## $ most_valuable_available_asset <dbl> 2, 1, 1, 1, 2, 1, 1, 1, 3, 4, 1, 3, …
## $ age_years <dbl> 21, 36, 23, 39, 38, 48, 39, 40, 65, …
## $ concurrent_credits <dbl> 3, 3, 3, 3, 1, 3, 3, 3, 3, 3, 3, 3, …
## $ type_of_apartment <dbl> 1, 1, 1, 1, 2, 1, 2, 2, 2, 1, 1, 1, …
## $ no_of_credits_at_this_bank <dbl> 1, 2, 1, 2, 2, 2, 2, 1, 2, 1, 2, 2, …
## $ occupation <dbl> 3, 3, 2, 2, 2, 2, 2, 2, 1, 1, 3, 3, …
## $ no_of_dependents <dbl> 1, 2, 1, 2, 1, 2, 1, 2, 1, 1, 2, 1, …
## $ telephone <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
## $ foreign_worker <dbl> 1, 1, 1, 2, 2, 2, 2, 2, 1, 1, 1, 1, …Assess the creditabiliy with the help of other variables
# code -------------------------------------------------------------------------
ggplot(data = Data, aes(x = age_years, color = creditability, fill = creditability)) +
geom_histogram(binwidth = 5, position = "identity", alpha = 0.4) +
scale_x_continuous(breaks = scales::pretty_breaks(n = 6)) +
scale_y_continuous(breaks = scales::pretty_breaks(n = 6)) + theme_minimal()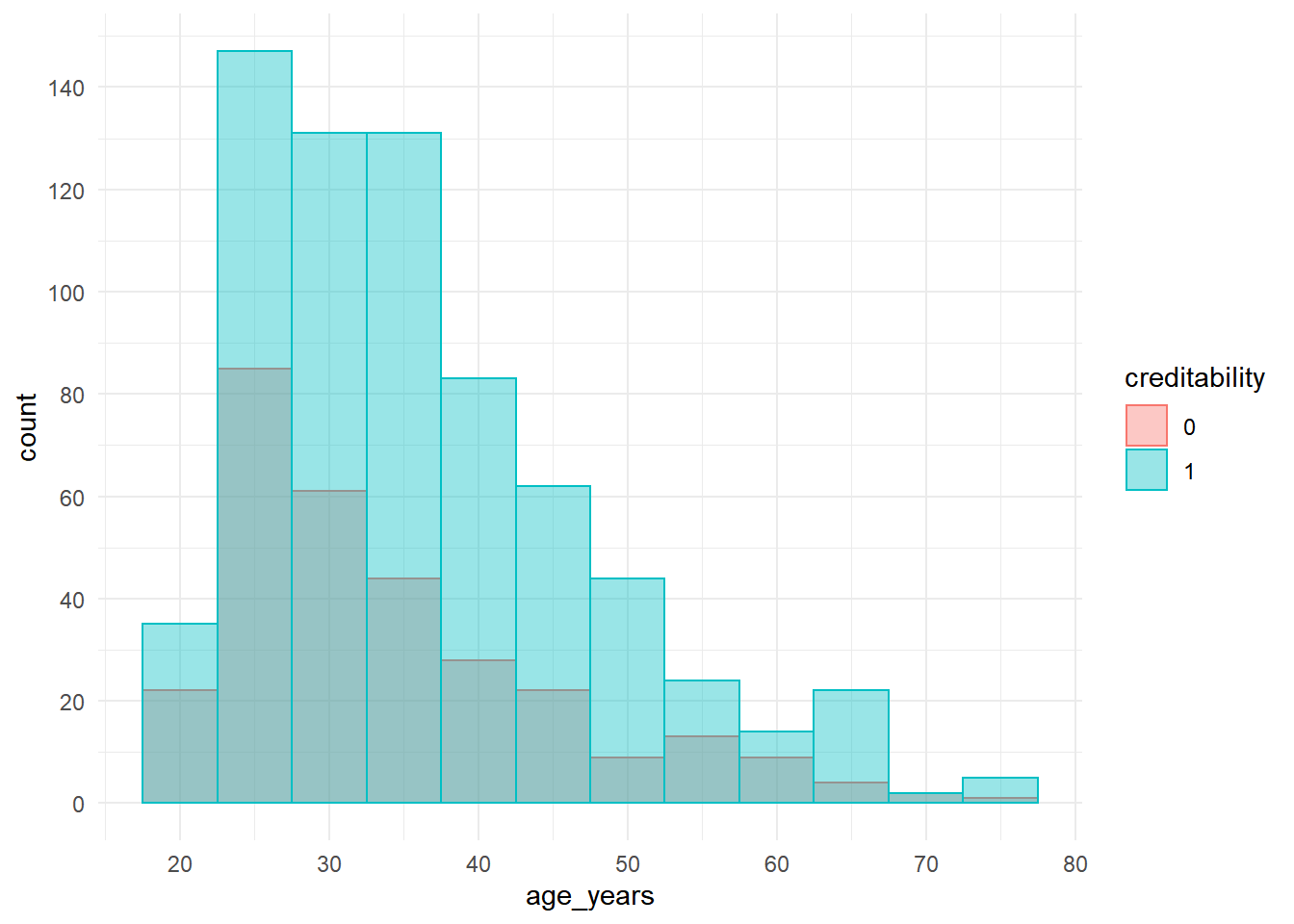
# Create a training and testing data
set.seed(7791)
partitioning <- sample(2, nrow(Data), replace = TRUE, prob = c(0.8, 0.2))
table(partitioning)
## partitioning
## 1 2
## 797 203
train <- Data[partitioning == 1, ]
table(train$creditability)
##
## 0 1
## 244 553
test <- Data[partitioning == 2, ]
table(test$creditability)
##
## 0 1
## 56 147Train the Random forest model
# Generate random forest with train data
rf_model <- randomForest(formula = creditability ~ ., data = train)
predict_train <- predict(rf_model, train)
confusionMatrix(predict_train, train$creditability)
## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 244 0
## 1 0 553
##
## Accuracy : 1
## 95% CI : (0.9954, 1)
## No Information Rate : 0.6939
## P-Value [Acc > NIR] : < 2.2e-16
##
## Kappa : 1
##
## Mcnemar's Test P-Value : NA
##
## Sensitivity : 1.0000
## Specificity : 1.0000
## Pos Pred Value : 1.0000
## Neg Pred Value : 1.0000
## Prevalence : 0.3061
## Detection Rate : 0.3061
## Detection Prevalence : 0.3061
## Balanced Accuracy : 1.0000
##
## 'Positive' Class : 0
## Testing the model rf_model on test data
predict_test <- predict(rf_model, test)
confusionMatrix(predict_test, test$creditability)
## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 28 12
## 1 28 135
##
## Accuracy : 0.803
## 95% CI : (0.7415, 0.8553)
## No Information Rate : 0.7241
## P-Value [Acc > NIR] : 0.006157
##
## Kappa : 0.459
##
## Mcnemar's Test P-Value : 0.017706
##
## Sensitivity : 0.5000
## Specificity : 0.9184
## Pos Pred Value : 0.7000
## Neg Pred Value : 0.8282
## Prevalence : 0.2759
## Detection Rate : 0.1379
## Detection Prevalence : 0.1970
## Balanced Accuracy : 0.7092
##
## 'Positive' Class : 0
##
# Reference
# Prediction 0 1
# 0 29 14
# 1 27 133
varImpPlot(rf_model)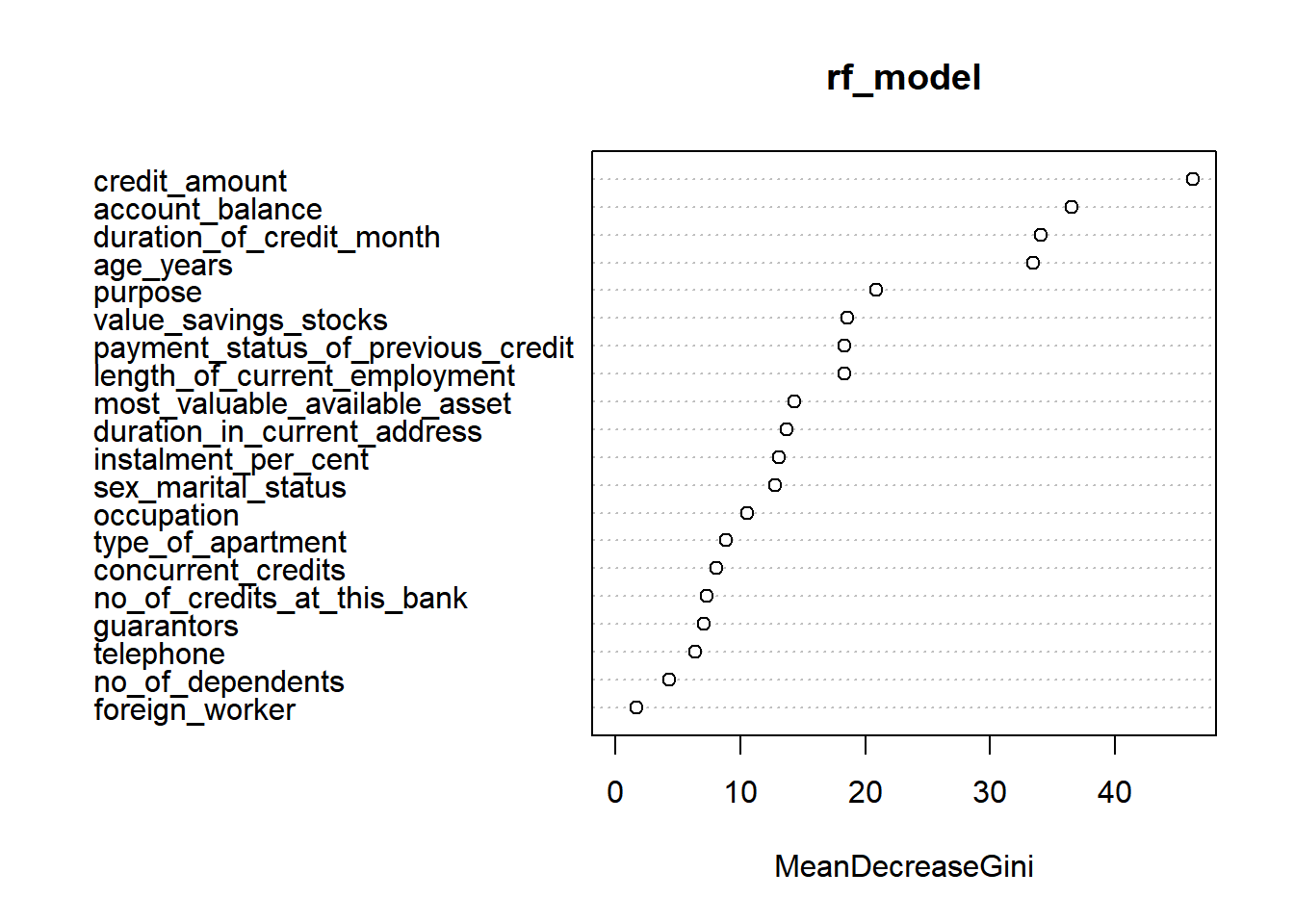
Optimize the performance of randomforest.
plot(rf_model) # black line is out of bag error.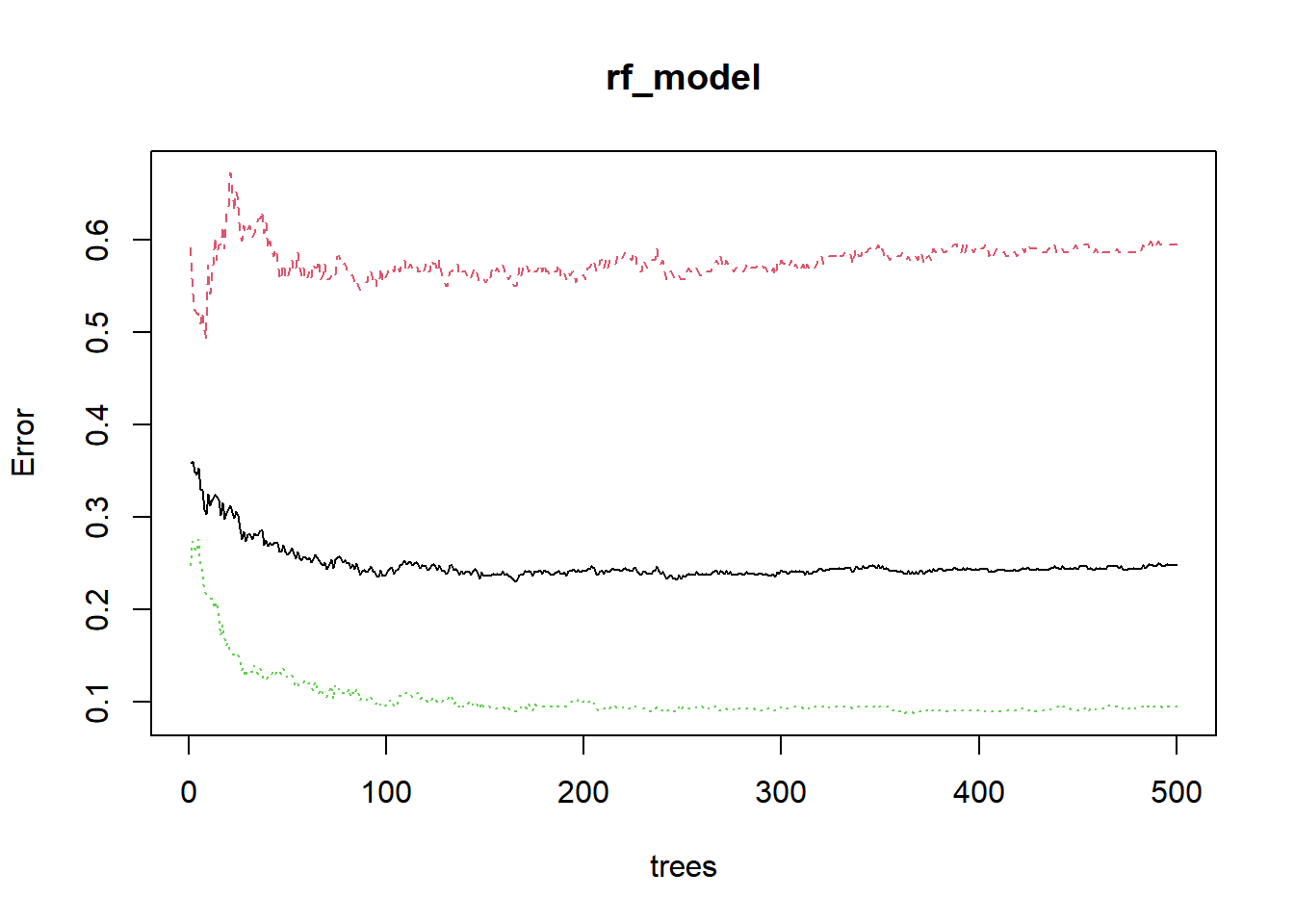
oob_error <- double(20)
for (mtry in 1:20) {
rf <- randomForest(formula = creditability ~ ., data = train, mtry = mtry, ntree = 166)
oob_error[mtry] <- rf$err.rate[166]
}
plot(1:20, oob_error, type = "b", xlab = "Number of variable considered", ylab = "Out of bag erro [-]", xaxt = "n")
axis(1, at = 1:20, labels = 1:20, cex = 0.8)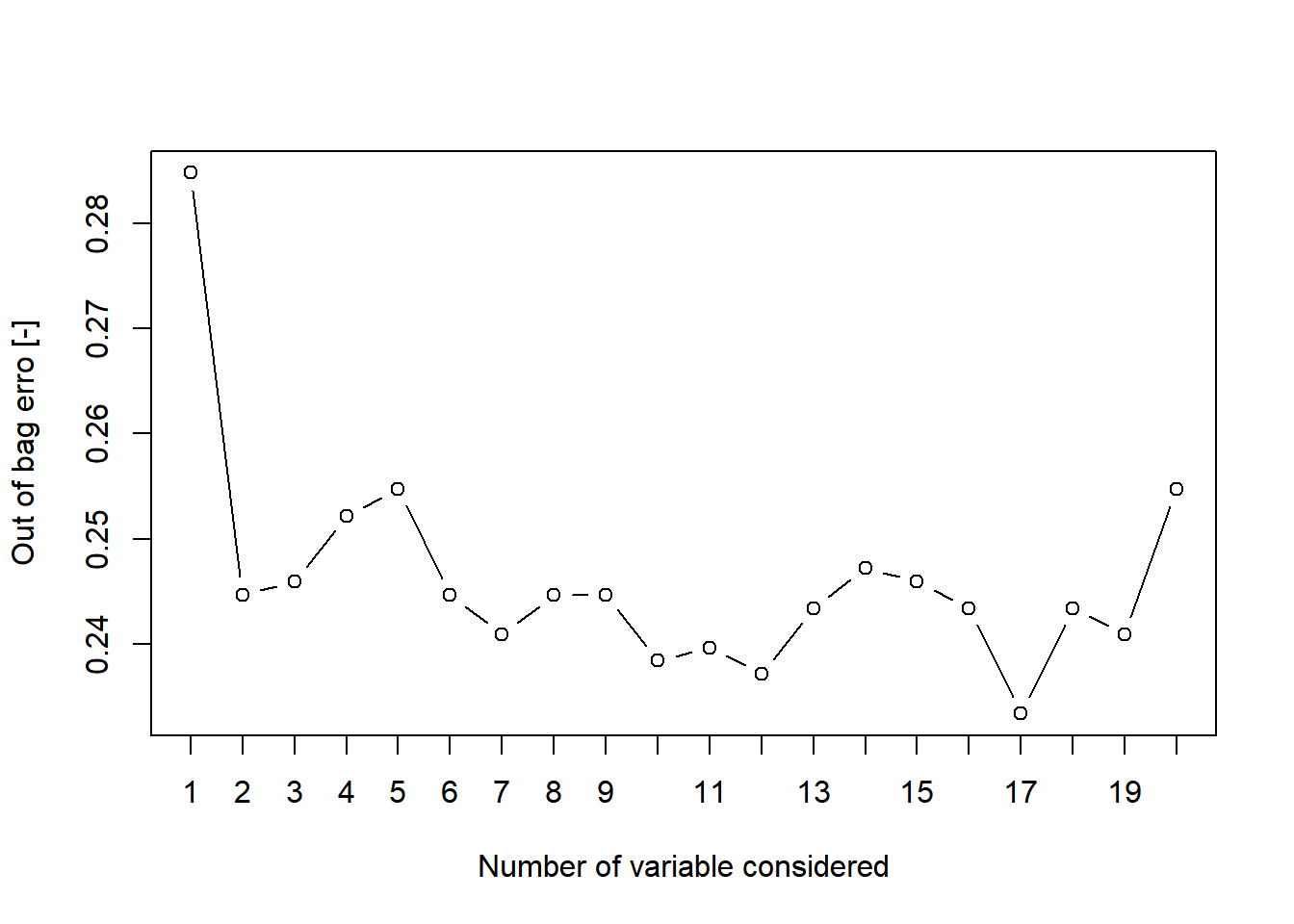
opti_num_var = which.min(oob_error)Re running the random forest with optimum number of variables
rf_optim <- randomForest(formula = creditability ~ ., data = train, mtry = opti_num_var, ntree = 166)
# Testing the model `rf_model` on test data
confusionMatrix(predict(rf_optim, test), test$creditability)
## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 33 20
## 1 23 127
##
## Accuracy : 0.7882
## 95% CI : (0.7255, 0.8423)
## No Information Rate : 0.7241
## P-Value [Acc > NIR] : 0.02266
##
## Kappa : 0.4609
##
## Mcnemar's Test P-Value : 0.76037
##
## Sensitivity : 0.5893
## Specificity : 0.8639
## Pos Pred Value : 0.6226
## Neg Pred Value : 0.8467
## Prevalence : 0.2759
## Detection Rate : 0.1626
## Detection Prevalence : 0.2611
## Balanced Accuracy : 0.7266
##
## 'Positive' Class : 0
## Exploring useful variables
train <- as.data.frame(train)
varImpPlot(rf_model)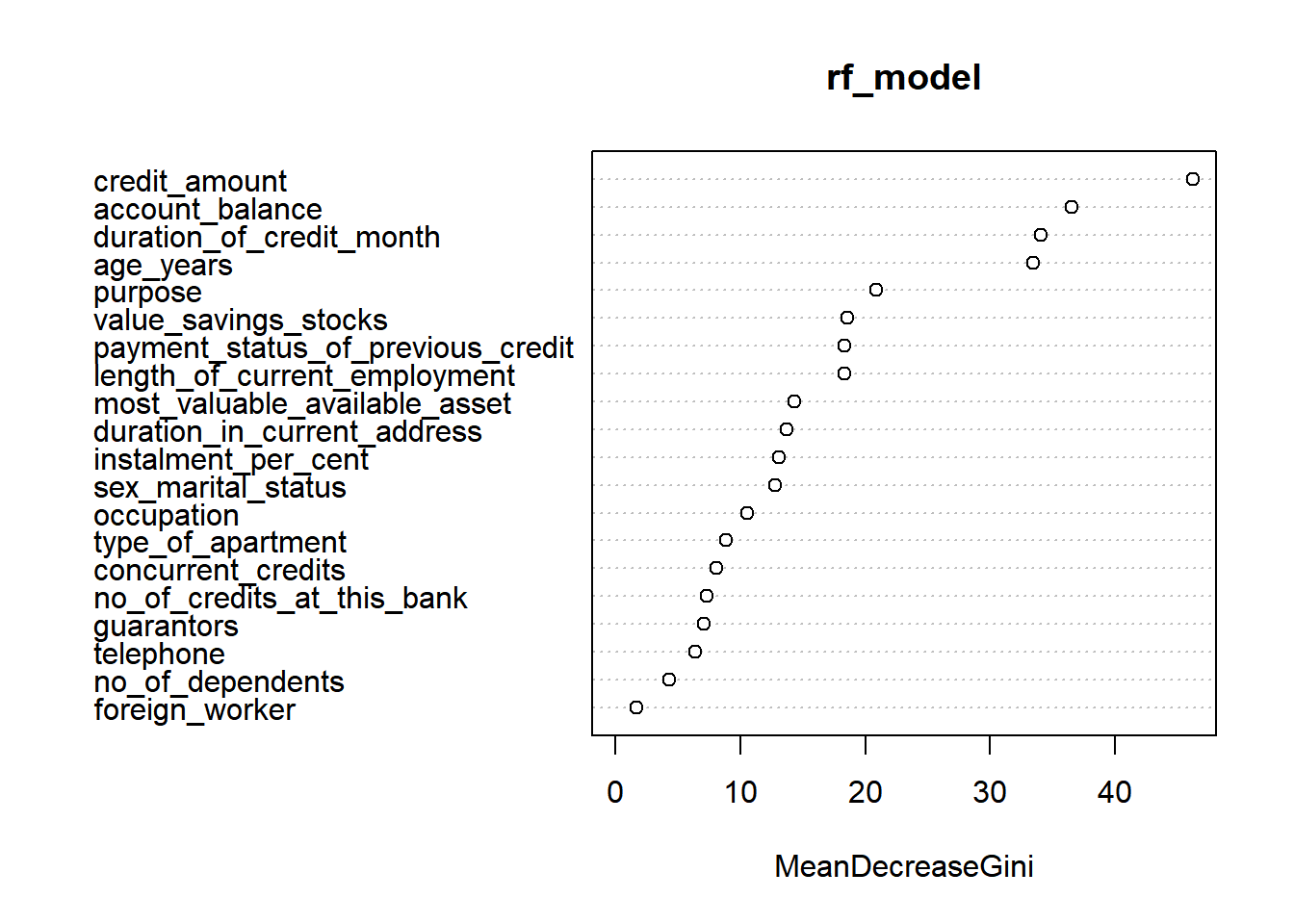
importance(rf_model)
## MeanDecreaseGini
## account_balance 36.543019
## duration_of_credit_month 34.072986
## payment_status_of_previous_credit 18.303982
## purpose 20.837156
## credit_amount 46.208519
## value_savings_stocks 18.564843
## length_of_current_employment 18.296281
## instalment_per_cent 13.122638
## sex_marital_status 12.781397
## guarantors 7.055415
## duration_in_current_address 13.666627
## most_valuable_available_asset 14.340330
## age_years 33.451374
## concurrent_credits 8.064289
## type_of_apartment 8.821601
## no_of_credits_at_this_bank 7.306201
## occupation 10.567355
## no_of_dependents 4.325819
## telephone 6.359517
## foreign_worker 1.666973
# How variable affect the chance of getting loan.
partialPlot(rf_model, train, account_balance, "1")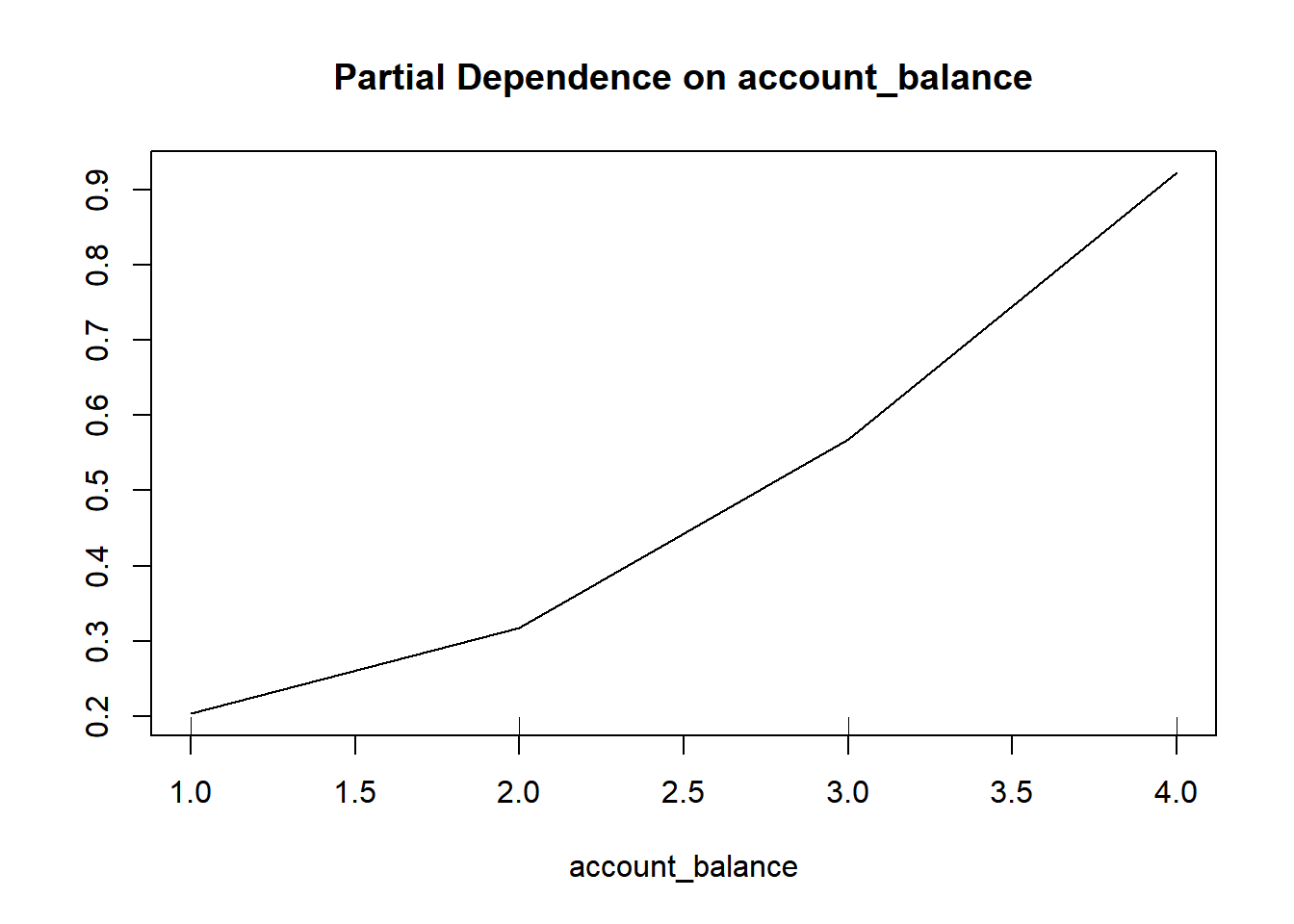
partialPlot(rf_model, train, age_years, "1")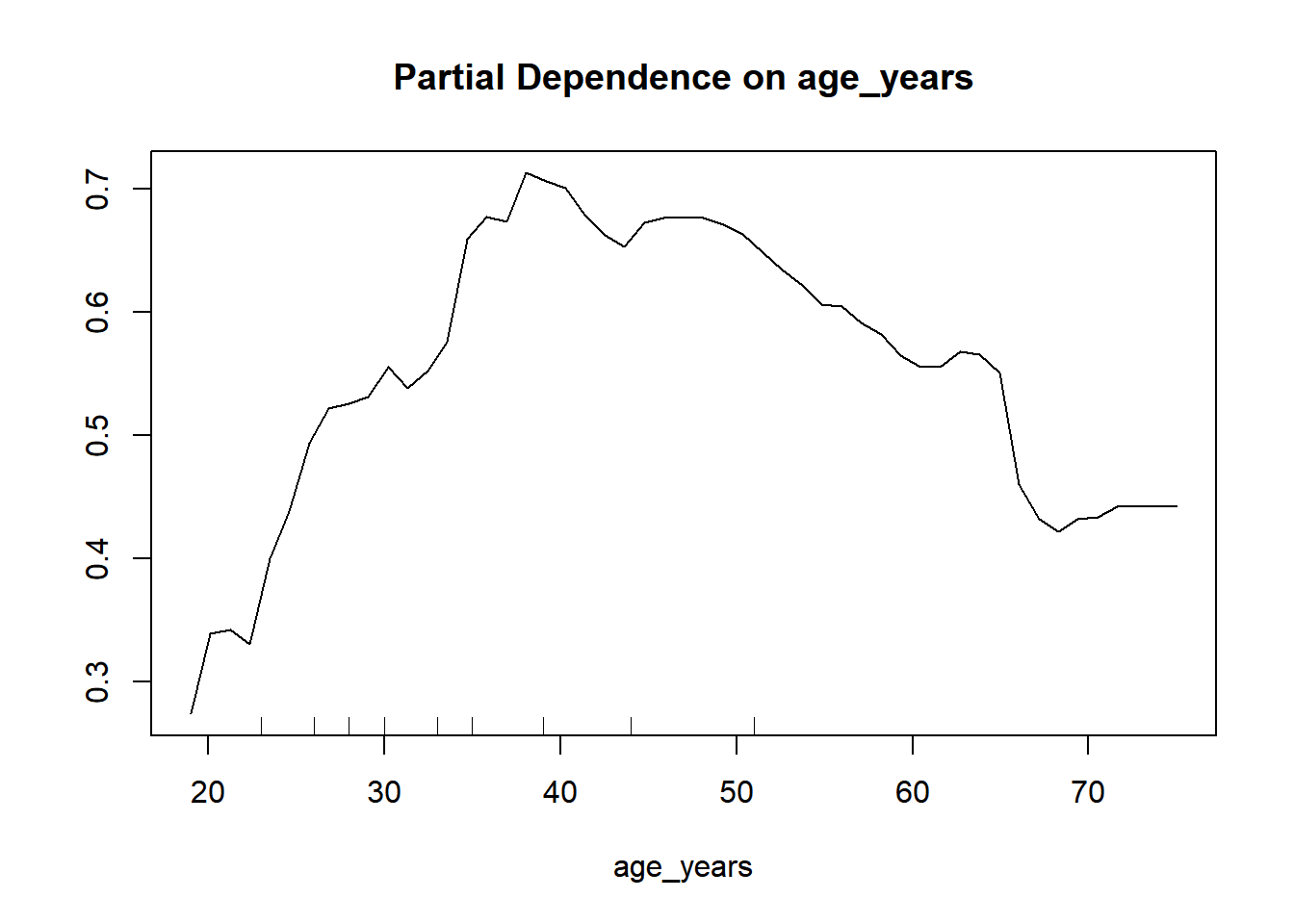
This analysis for discrete variable of creditability.